Efficient scaling of embedding models has been a core research focus of Voyage AI by MongoDB: Rather than simply scaling up, we aim to improve the quality-cost trade-off—extending the Pareto frontier beyond what is possible with standard architectures. In the Voyage 3.5 series, we pushed the scaling trends of traditional dense embedding models to their practical limits. To further push the Pareto frontier, we introduced a mixture-of-experts (MoE) architecture in voyage-4-large.
In this blog post, we are excited to share more insights on how we incorporate MoE and use it to improve scaling efficiency.
- First, we discuss the concepts of dense and MoE embedding models.
- Next, we walk through the design choices of implementing MoE embedding models, including how we optimize them during voyage-4-large development.
- Finally, we perform a scaling study of our recipe and share the resulting scaling improvements: a 75% reduction in the number of active parameters with almost the same retrieval accuracy compared with dense embedding models.
MoE embedding models explained
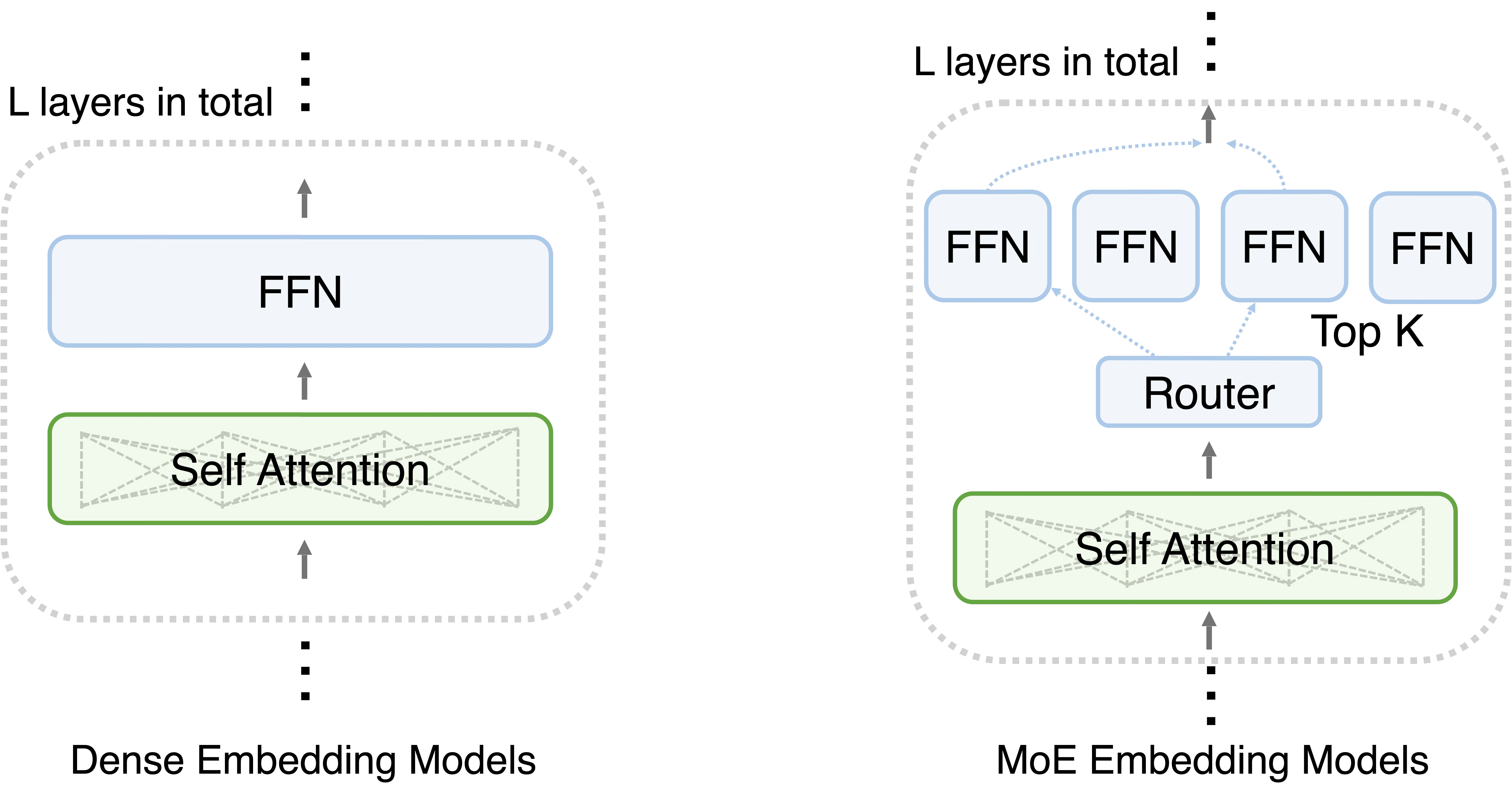
Traditional dense embedding models are composed of interleaved bidirectional self-attention—which enables every token in a sequence to “attend” to every other token—and dense feed-forward network (FFN) layers. In dense FFN, every single input token triggers a pass through every parameter. This creates a linear relationship between the model’s parameter count and its computational cost, making it difficult to scale without a massive increase in hardware requirements. Better model quality has to come with higher compute cost and longer inference latency.
The MoE embedding models replace the dense FFN with a sparse MoE FFN layer. This layer consists of two primary components: a router (or gating network) and a collection of independent expert FFNs. When a token enters the layer, the router calculates which experts are best suited to process that specific information and directs the token accordingly. This introduces a distinction between total parameters (all experts available in the model) and active parameters (only the experts actually used for a specific token). For example, a model might have 100 billion total parameters, but only activate 10 billion per token, significantly reducing the computational workload for training and inference. Practically, the activation ratio (the ratio between number of activated parameters and number of total parameters) is used to characterize the degree of sparsity of MoE models. In modern MoE models, the industry-standard activation ratio is 1/10.
The intuition of MoE is the decoupling of computational cost from knowledge capacity. In terms of cost and latency, we only “pay” (in terms of FLOPs and latency) for the active parameters during training and inference. However, the model’s actual “intelligence”—its ability to store facts, nuances, and specialized domain knowledge—is more closely tied to its total parameters. This enables MoE embeddings to offer the “brain power” of a massive model with the operating cost of a much smaller one.
Figure 1. Dense embedding models vs. MoE embedding models.
Design choices in implementing MoE
Following industry convention, we adopt standard top-k routing and set the activation ratio of voyage-4-large to 1/10. However, the implementation of MoE embeddings in production introduces more nuanced design choices. In this section, we discuss several key design choices we made during voyage-4-large development.
Token dropping: Trade-off between model flops utilization and retrieval accuracy
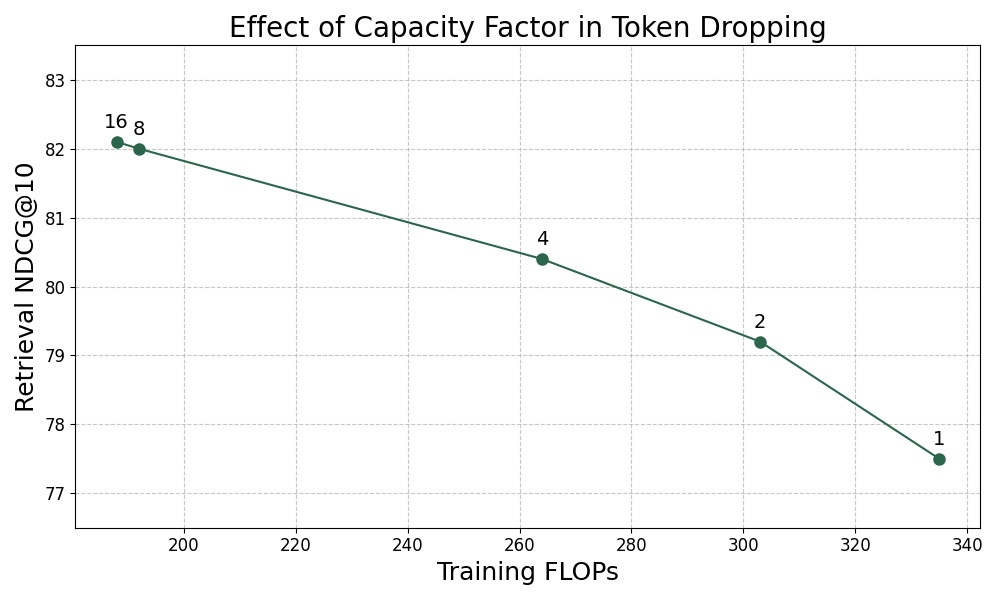
In MoE training, token dropping serves as a lever for balancing training efficiency against model accuracy. Although modern MoE is equipped with sophisticated load balancing auxiliary losses, imbalances still occur occasionally on outlier inputs, where a few experts receive more tokens than their defined capacity. In such cases, the GPU hosting those “popular” experts will become overloaded, reducing the GPU utilization of the whole system.
A straightforward approach to address this is to set a capacity factor that limits the number of tokens each expert can process. When the number of tokens assigned to an expert exceeds this limit, the MoE layer simply drops the overflow tokens. This ensures that the computation remains predictable and synchronous, preventing a few overloaded GPUs from bottlenecking the entire cluster. However, the cost of this efficiency is a loss of information. Dropped tokens bypass the experts, falling back to a residual connection. This might lead to degradation in model quality.
Below, we present how capacity factors affect training throughput and retrieval accuracy. We observed a significant retrieval accuracy degradation with a small capacity factor, although the throughput is much improved. With a larger capacity factor, we can retain almost all retrieval accuracy while improving throughput. Eventually, we used the maximum possible capacity factor to avoid performance degradation.
Figure 2. The effect of capacity factor in token dropping.
Router freezing and model merging
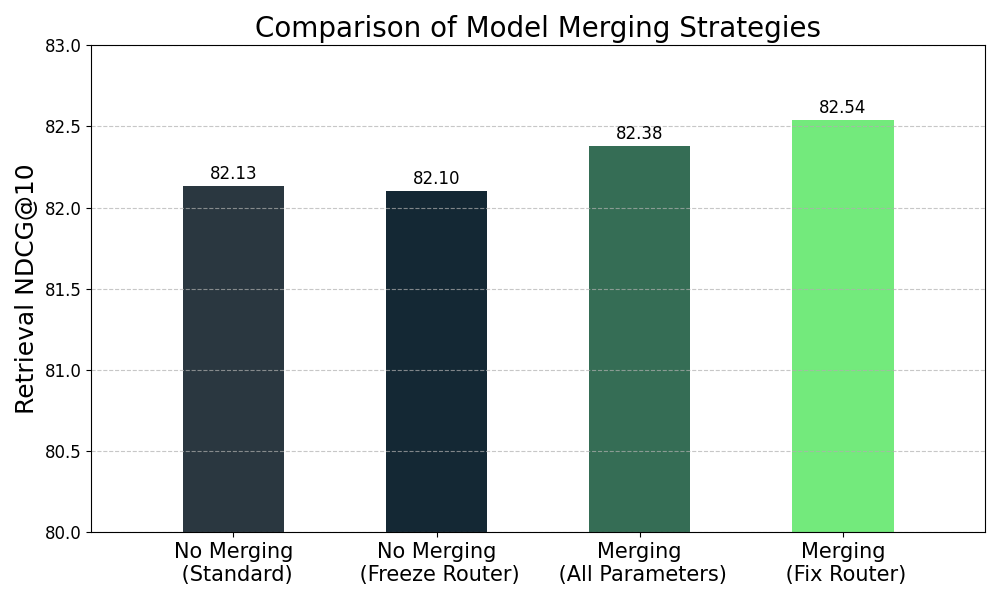
Model merging is a common technique to achieve better overall performance using a set of source models fine-tuned with slightly different data and hyperparameters. For traditional dense embeddings, all parameters of the final merged model come from interpolation of source-model parameters. In MoE embeddings, routers might make model merging more complicated. Routers decide which experts the tokens are routed to. Expert selection can be very sensitive to router parameter changes. To mitigate this effect, we slightly tweaked the pipeline for merging models.
Embedding model training comprises several stages, with model merging happening after the final stage. We keep training the router parameters in all but the last stage, and we fix them for the final stage. Therefore, router parameters remain unchanged after model merging.
Below, we compare how different merging strategies affect final performance. First, fixing router parameters in the final stage does not affect retrieval quality prior to merging. Second, the merged model from the proposed method outperforms training and merging all parameters in the final stage.
Figure 3. Comparison of model merging strategies.
Scaling results
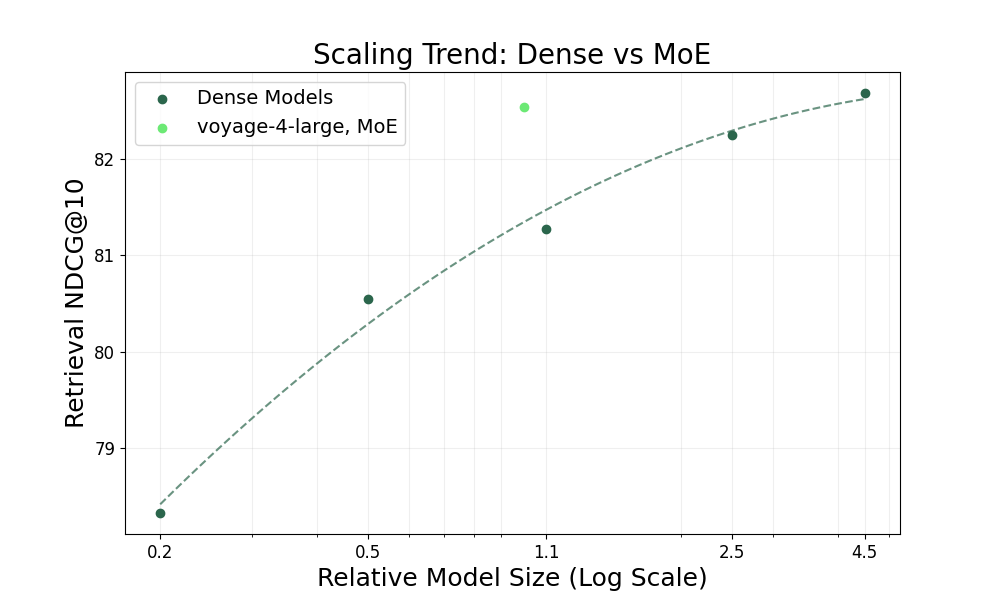
Integrating all design choices above, we evaluated how much MoE improves the scaling trend of embedding models. We trained a series of dense embedding models across various sizes with the same recipe of voyage-4-large, and we benchmarked their average retrieval accuracy on the evaluation suite introduced in the Voyage 3.5 blog post. We characterized “effective size” by total parameters for dense models and active parameters for MoE models to better reflect inference latency and cost. We reported the average NDCG@10 across these relative scales, normalized to the size of voyage-4-large.
As shown in the figure below, dense embedding models demonstrate a linear scaling trend to the log of the number of parameters. Equipped with MoE, voyage-4-large has comparable retrieval accuracy to a dense model with 4x more active parameters trained with the same recipe. This implies that, compared with dense embedding models with the same retrieval accuracy, the MoE architecture introduced in voyage-4-large leads to a 75% reduction in inference cost and latency.
Figure 4. Scaling trend: Dense vs. MoE.
Conclusion
In this blog post, we introduced design choices we studied during the development of voyage-4-large and studied how using MoE leads to a big leap in scaling efficiency. By decoupling knowledge capacity from computational cost, we achieved a 75% reduction in active parameters per token compared to a dense model of equivalent retrieval accuracy. This shift enables us to deliver state-of-the-art performance while drastically lowering the computational overhead typically associated with large-scale dense embeddings.
Next Steps
To learn more about voyage-4-large, read the launch blog or head over to the docs.