We are excited to announce the public preview of Automated Embedding in MongoDB Vector Search (available in Public Preview in MongoDB Community Edition), a groundbreaking feature designed to make building sophisticated, AI-powered applications easier than ever. Since 2023, MongoDB has offered integrated vector search alongside our operational database, and last year we announced the acquisition of Voyage AI, bringing state-of-the-art embedding and reranking models to our customers.
Now, with Automated Embedding in MongoDB Vector Search and the integration of Voyage AI’s state-of-the-art models, we’re giving developers a feature which solves a major point of friction: one-click automatic embedding directly inside MongoDB, which eliminates the need to sync data and manage external models.
Automated Embedding in MongoDB Vector Search
At its core, Automated Embedding in Vector Search offers seamless, secure, and scalable AI-powered search natively in MongoDB. By automatically generating vector embeddings (numerical representations of your data to capture semantic meaning), we eliminate the significant complexity typically required when building semantic search, recommendation engines, RAG apps, and AI agents.
The complexity we’re eliminating
Before this release, building vector search into applications presented significant challenges:
Manual embedding generation: Choosing an embedding model from over 100 available options and figuring out how to integrate external API services (authentication, input payload, output parameters) is challenging. Developers had to generate embeddings using external providers as part of their application code before inserting data or querying vector search.
Synchronization overhead: Every insert, update, or delete required keeping source data and vector embeddings in sync. Developers had to set up custom pipelines, monitor change streams, and write logic to trigger re-embedding and synchronize vectors every time source data changed.
Additional API complexity: Each vector search query necessitated an extra API call to generate query embeddings.
Managing large data ingestion: While simple embedding creation can be straightforward, embedding millions of documents becomes a production nightmare that developers need to monitor at scale. Teams must build complex MLOps pipelines with queuing systems, specialized workers, and retry logic to handle failures, integrate monitoring and alert systems, and ensure that primary database operations aren't blocked by slow or failing embedding endpoints.
The Solution: Streamlined AI-powered search
Automating the embedding process reduces complexity and makes getting started with semantic search as simple as creating a vector search index.
For the first time, you can simply choose an embedding model while setting up a vector search index, and the entire embeddings generation process is automated—no longer needing to rely on different vendors for embedding models and vector databases, which adds complexity and integration risks. Now, you can simply select the embedding model that best matches your needs, including best-in-class embedding models from Voyage AI. This simplified approach significantly reduces the effort required to get started with key AI use cases, while Voyage AI's industry-leading embedding models ensure high-accuracy retrieval.
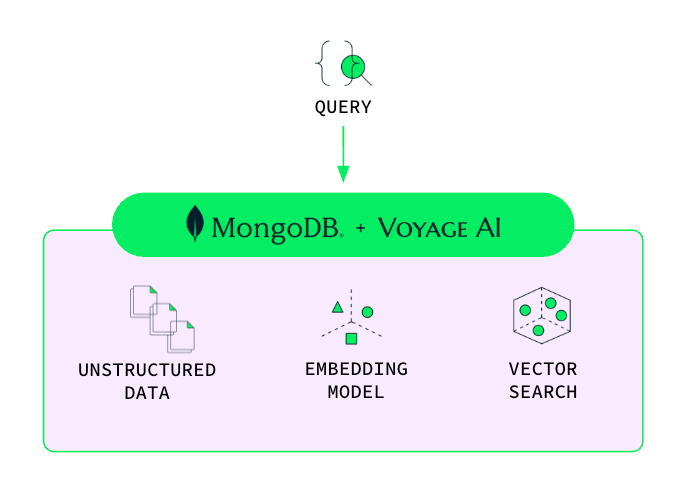
Offers architectural simplicity
Our streamlined architecture eliminates the need to manage separate embedding generation workflows, especially when handling complex, high-volume ingestions.
Developers no longer need to maintain external embedding models, freeing up valuable engineering time that was previously spent on custom pipelines, complex error handling, and performance tuning. This simplification allows you to focus on improving application functionality rather than building embeddings from scratch or having to bring in external third parties. With MongoDB, you now get the benefits of OLTP database, vector search, and Voyage AI embedding models in one unified system, eliminating the need for multiple systems and messy data syncs.
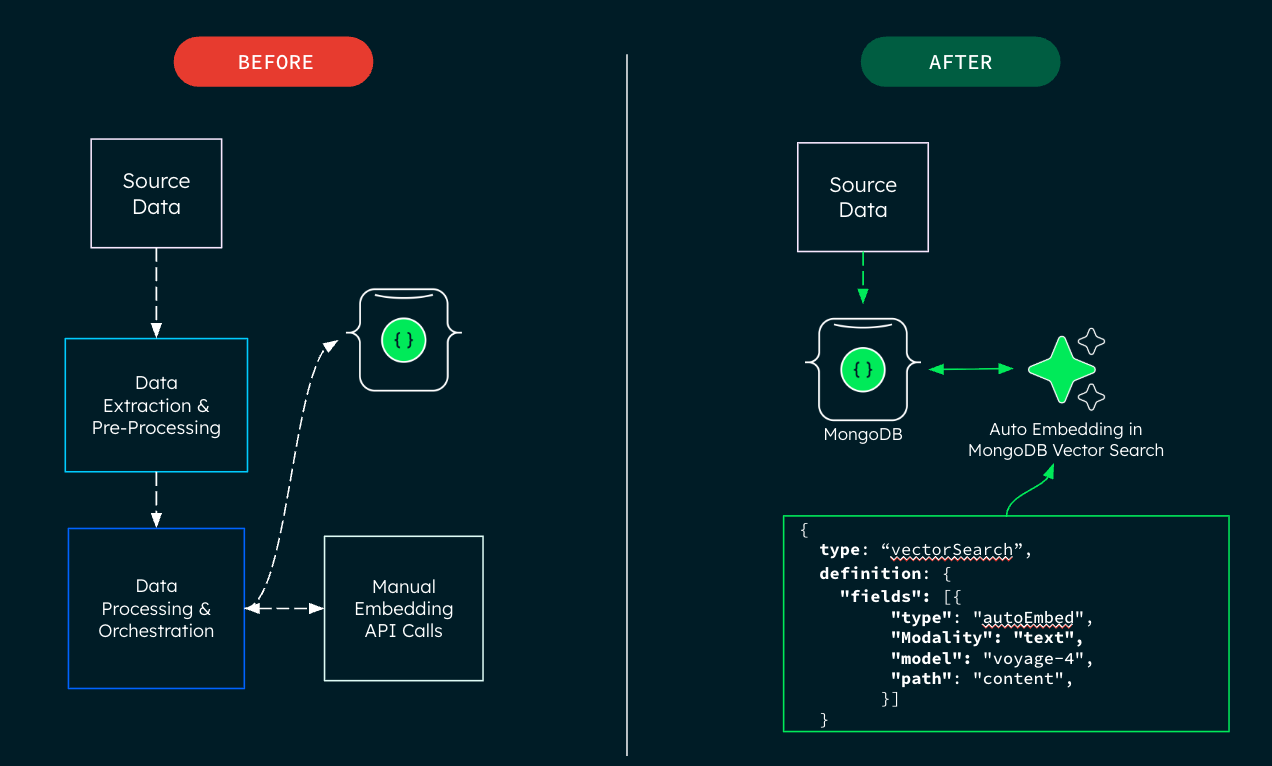
Eliminates embedding mismatches with automation
The system automatically generates vector embeddings for text data during initial data sync when creating indexes, during document insertions and updates, and during query processing. Vector embeddings stay synchronized as underlying data changes, eliminating the risk of stale or mismatched embeddings.
Powered by state-of-the-art Voyage AI embedding models
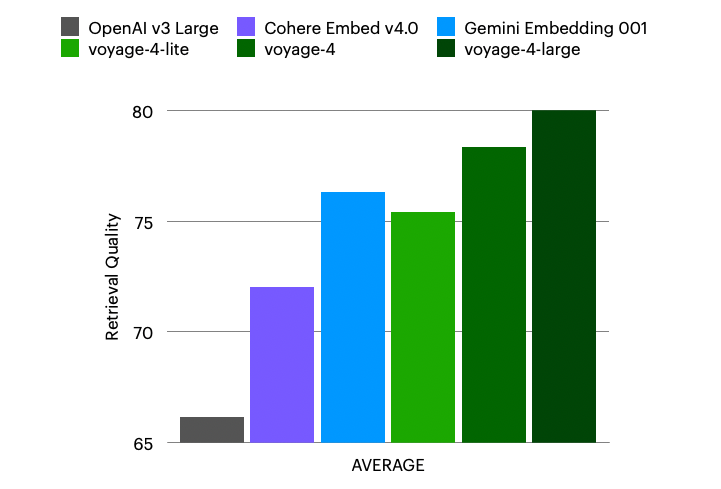
Automated Embedding in MongoDB Vector Search features state-of-the-art embedding models from Voyage AI, including voyage-4-large, voyage-4, voyage-4-lite and voyage-code-3. These models deliver industry-leading performance on retrieval benchmarks (such as RTEB) with multilingual support.
Optimized for performance and reliability
Automated Embedding in MongoDB Vector Search eliminates the context window and rate-limiting headaches that plague direct API integrations.
Through asynchronous dynamic batch processing that optimizes for maximum tokens per request allowed for a model, the system achieves optimal throughput during index creation - automatically adjusting batch sizes based on document shape and size. With built-in automatic retries and error handling, your embedding operations run reliably without blocking primary database operations. This production-ready infrastructure means you can ingest millions of documents without building complex MLOps pipelines or monitoring systems.
Future-proofs your AI applications
With Automated Embedding in MongoDB Vector Search, you can create indexes across multiple models and compare them side-by-side, making it simple to find the optimal price-performance for your use case. Model lifecycle management becomes effortless with automatic re-embedding capabilities when upgrading to newer, better-performing models.
We know many users have delayed migrating from older embedding models precisely because of the complexity involved in re-embedding entire datasets across multiple services. Now transitioning to next-generation models requires no custom code or complex coordination across your data services, and you can compare the performance of different models on your own dataset.
Having automatic embedding available both when loading documents and querying is a huge time-saver. It lets us experiment and iterate quickly, without worrying about embedding management or additional infrastructure.
”Simplification for everyone
Automated Embedding in MongoDB simplifies vector search adoption, allowing Software Engineers, ML Engineers, and Data Scientists from large enterprises to startups to focus on building applications rather than managing embedding integrations. It provides a low-friction path to unlocking powerful AI-driven capabilities for a wide range of use cases, including:
Generative AI: Building RAG (retrieval augmented generation) systems.
E-commerce: Delivering personalized product recommendations.
Content management: Implementing robust semantic search capabilities.
Customer service: Creating sophisticated question-answering functionalities.
Data science: Professionals who need efficient ways to process large datasets and streamline the transition from prototyping with state-of-the-art models to production.
Migration path: Providing an easy migration path for existing text search users looking to upgrade to vector and hybrid search capabilities for improved relevance.
Reducing development overhead and speeding results
We invited a select number of customers across industries, including healthcare, financial services, transportation, and media, to test automated embedding and provide feedback during our private preview. These customers saw the massive benefits, including immediate performance enhancements and reduced overhead. Two preview customers had the following to say:
"We deployed MongoDB’s automated embedding in vector search across our 40‑million‑document corpus, converting weeks of engineering into a low‑maintenance, production‑grade workflow that materially improved retrieval speed and relevance while reducing development overhead.”
—Ohad Levinkron-Fisch
Vice President of R&D and AI
MedINT Medical Intelligence
"Being able to drop MongoDB’s automated embedding into an in-flight, production-scale system and see immediate performance and simplicity gains is huge - and we’re thrilled to deepen our partnership with MongoDB, given how much of our stack already runs on MongoDB."
—Joe Marta
Senior Director, Applied AI
Coalfire
How to get started with the Public Preview
By automatically generating and synchronizing vector embeddings using Voyage AI models, Automated Embedding in MongoDB Vector Search eliminates traditional vector search complexities. This secure and scalable solution is native to MongoDB, accelerating the creation of powerful AI-enabled applications and significantly improving the developer experience.
Automated Embedding in MongoDB Vector Search in Community Edition is available now, with MongoDB Atlas and MongoDB Vector Search in Enterprise Edition access coming soon. Use your favorite MongoDB language drivers (Python, JavaScript, Java, C#, and GoLang), AI frameworks like LangChain and LangGraph, and the MongoDB MCP server.
Jump in with our quick start guide.
Next Steps
Download MongoDB Search in Community today, or read our Vector search documentation to dive deeper.